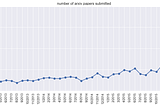
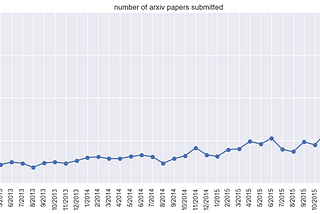
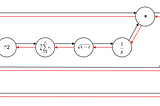
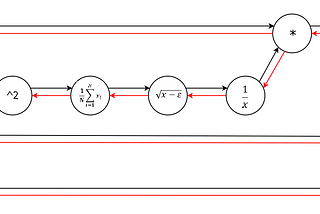
Andrej KarpathySoftware 2.0I sometimes see people refer to neural networks as just “another tool in your machine learning toolbox”. They have some pros and cons, they…Nov 11, 2017171Nov 11, 2017171
Andrej KarpathyAlphaGo, in contextUpdate Oct 18, 2017: AlphaGo Zero was announced. This post refers to the previous version. 95% of it still applies.May 31, 201718May 31, 201718
Andrej KarpathyICML accepted papers institution statsThe accepted papers at ICML have been published. ICML is a top Machine Learning conference, and one of the most relevant to Deep Learning…May 24, 20177May 24, 20177
Andrej KarpathyA Peek at Trends in Machine LearningHave you looked at Google Trends? It’s pretty cool — you enter some keywords and see how Google Searches of that term vary through time. I…Apr 7, 201710Apr 7, 201710
Andrej KarpathyICLR 2017 vs arxiv-sanityI thought it would be fun to cross-reference the ICLR 2017 (a popular Deep Learning conference) decisions (which fall into 4 categories…Mar 14, 20178Mar 14, 20178
Andrej KarpathyVirtual Reality: still not quite there, again.The first time I tried out Virtual Reality was a while ago — somewhere in the late 1990's. I was quite young so my memory is a bit hazy…Jan 17, 201718Jan 17, 201718
Andrej KarpathyYes you should understand backpropWhen we offered CS231n (Deep Learning class) at Stanford, we intentionally designed the programming assignments to include explicit…Dec 19, 201648Dec 19, 201648
Andrej KarpathyCS183c Assignment #3The last few weeks we heard from several excellent guests, including Selina Tobaccowala from Survey Monkey, Patrick Collison from Stripe…Nov 15, 20152Nov 15, 20152